






Build
Flyte enables you to build your data and ML workflows with robustness and scalability from the ground up. It hand-holds you throughout the creation process with best-in-class features.
Strongly typed interfaces
Validate your data at every step of the workflow by defining data guardrails using Flyte types. Integrate Flyte with Pandera and Great Expectations natively to perform in-depth validation and ensure that your data meets the necessary standards.
`float` and `int` types don’t match, hence compilation results in a type mismatch error.
Any language
You should be able to adopt the programming language of your choice to orchestrate data and ML workflows. Flyte lets you write code in any language using raw containers, or choose Python, Java, Scala or JavaScript SDKs to develop your Flyte workflows. You can use the languages you are most comfortable with, making it easier to design and manage your workflows.

“We got over 66% reduction in orchestration code when we moved to Flyte — a huge win!”
Seth Miller-Zhang, Senior Software Engineer at ZipRecruiter
Map tasks
Parallel processing is useful for scenarios from hyperparameter optimization and complex data processing. Flyte’s map tasks enable parallel processing by dividing larger computations into independent pieces.
Run a task in parallel by enclosing it in `map_task` construct.
Dynamic workflows
Dynamism in DAGs is crucial to building dynamic workflows, particularly in ML. Build dynamic DAGs in Flyte effortlessly using the `@dynamic` decorator. This allows you to create flexible and adaptable workflows that can change and evolve as needed, making it easier to respond to changing requirements.
A dynamic workflow to compute cross-validation scores across different models.
Branching
The `conditional` statement in Flyte allows you to selectively execute branches of your workflow based on static or dynamic data produced by other tasks or input data. That’s useful when you need to make decisions based on the results of previous tasks, or on external data.
Based on the outcome of the data validation, the conditional statement selects the appropriate task to execute.
FlyteFile & FlyteDirectory
Flyte simplifies the process of transferring files and directories between local and cloud storage. It establishes a seamless connection and streamlines the movement of data from one to the other.
Eliminate the need for boilerplate code when downloading and uploading files and directories with Flyte.
“FlyteFile is a really nice abstraction on a distributed platform. [I can say,] ‘I need this file,’ and Flyte takes care of downloading it, uploading it and only accessing it when we need to. We generate large binary files in netcdf format, so not having to worry about transferring and copying those files has been really nice.”
Nicholas LoFaso, Senior Platform Software Engineer at MethaneSAT
Structured dataset
Effortlessly convert dataframes between types and enforce column-level type checking using the abstract 2D representation provided by Structured Dataset. Extract subsets of columns and specify the storage backend, all without the need to write boilerplate code.
A Vaex dataframe can easily be converted to a Pandas dataframe.
Wait for external inputs
You might need your execution to halt, wait for external inputs, or await manual approval. By using `sleep()`, `wait_for_input()`, and `approve()`, you can pause execution for a specified duration, wait for external input signals, and necessitate explicit approval before resuming execution, respectively.
ImageSpec
Data scientists and ML practitioners often find Dockerfiles challenging. With Flyte’s `ImageSpec`, you can create images without needing Dockerfiles. You can define Python packages, apt packages and environment variables directly in the `ImageSpec`.
Iterate
Make workflow orchestration a collaborative experience. Don’t struggle to iterate on your data and ML workflows with your team. Leverage the native features to accelerate your development cycles.
Recover from failures
Debugging can be time-consuming and costly — more so if it involves rerunning successful tasks. Flyte makes it easy to recover from failures by allowing you to rerun only the failed tasks in a workflow. Simply click the Recover button on the user interface, and Flyte will automatically recover the successful tasks and rerun only the failed tasks. This can save you time and resources, and make debugging more efficient.
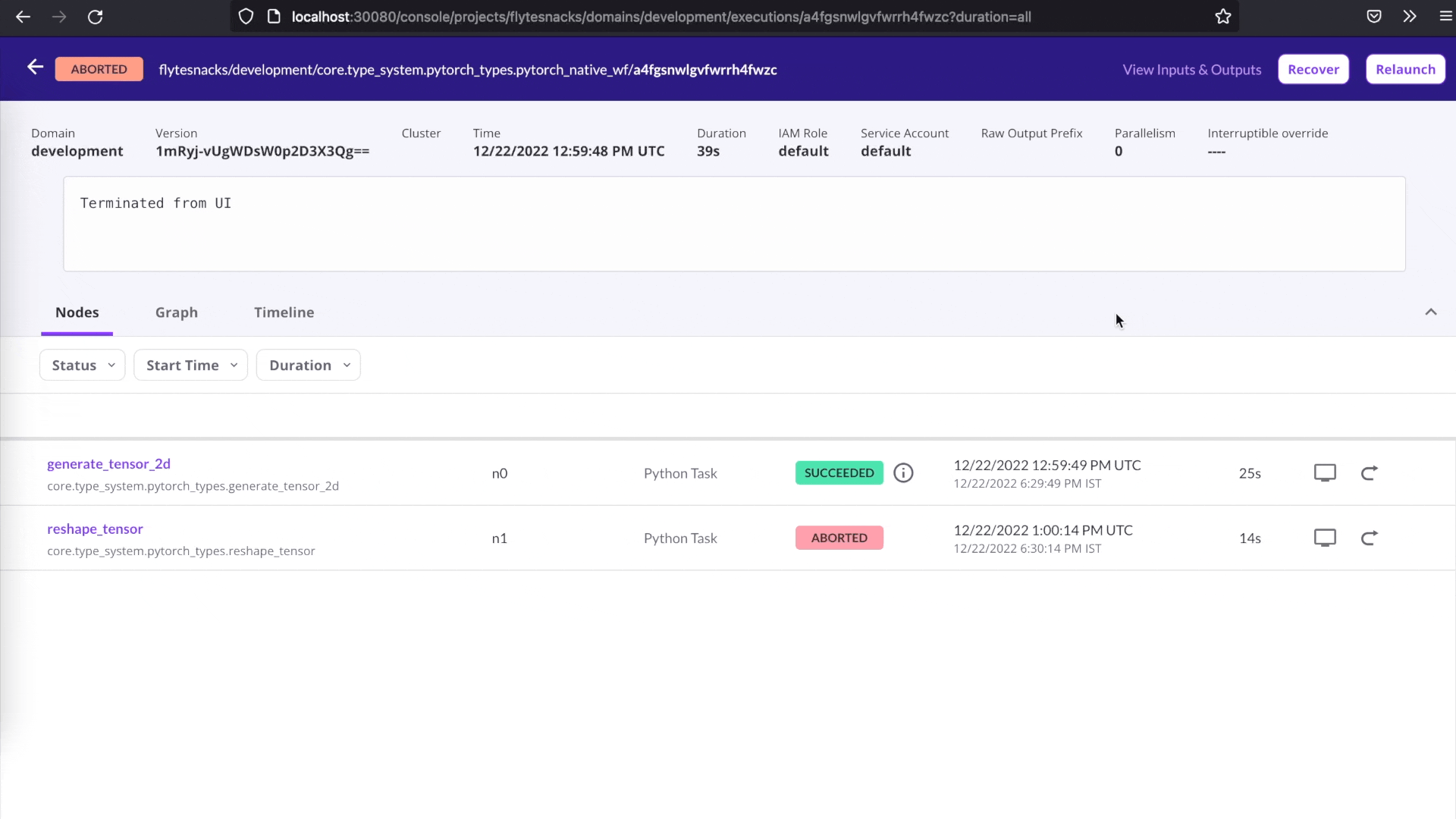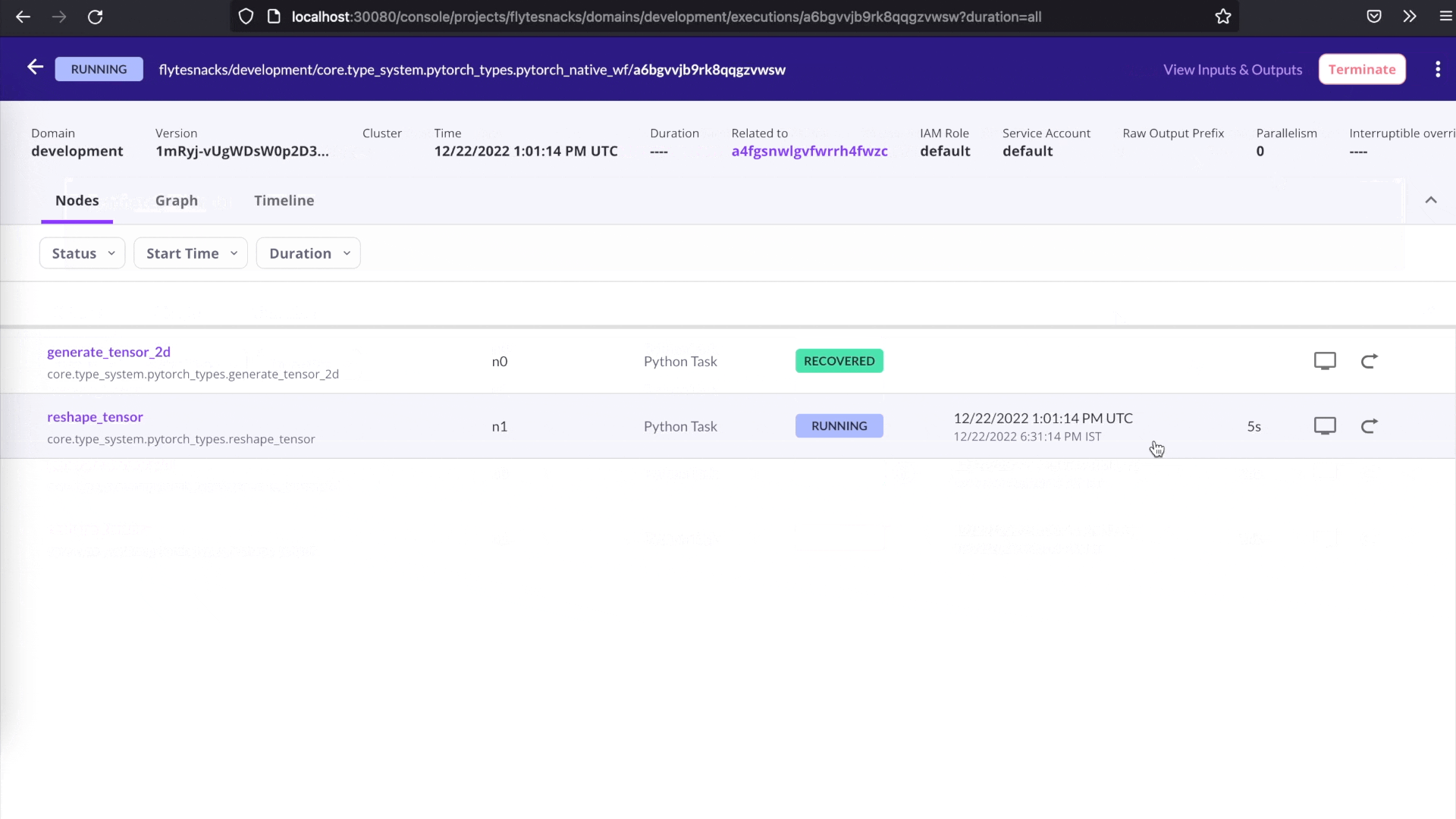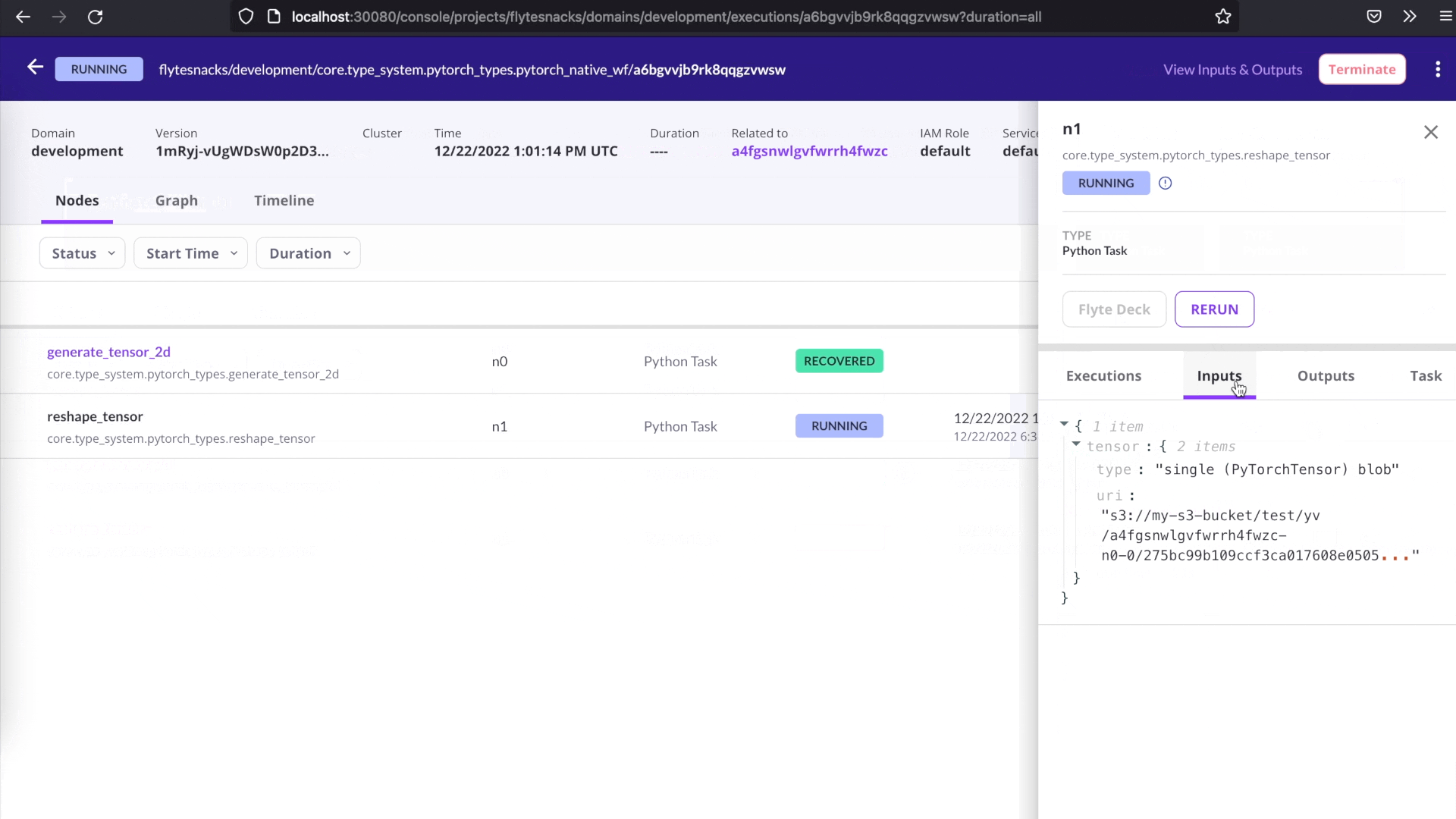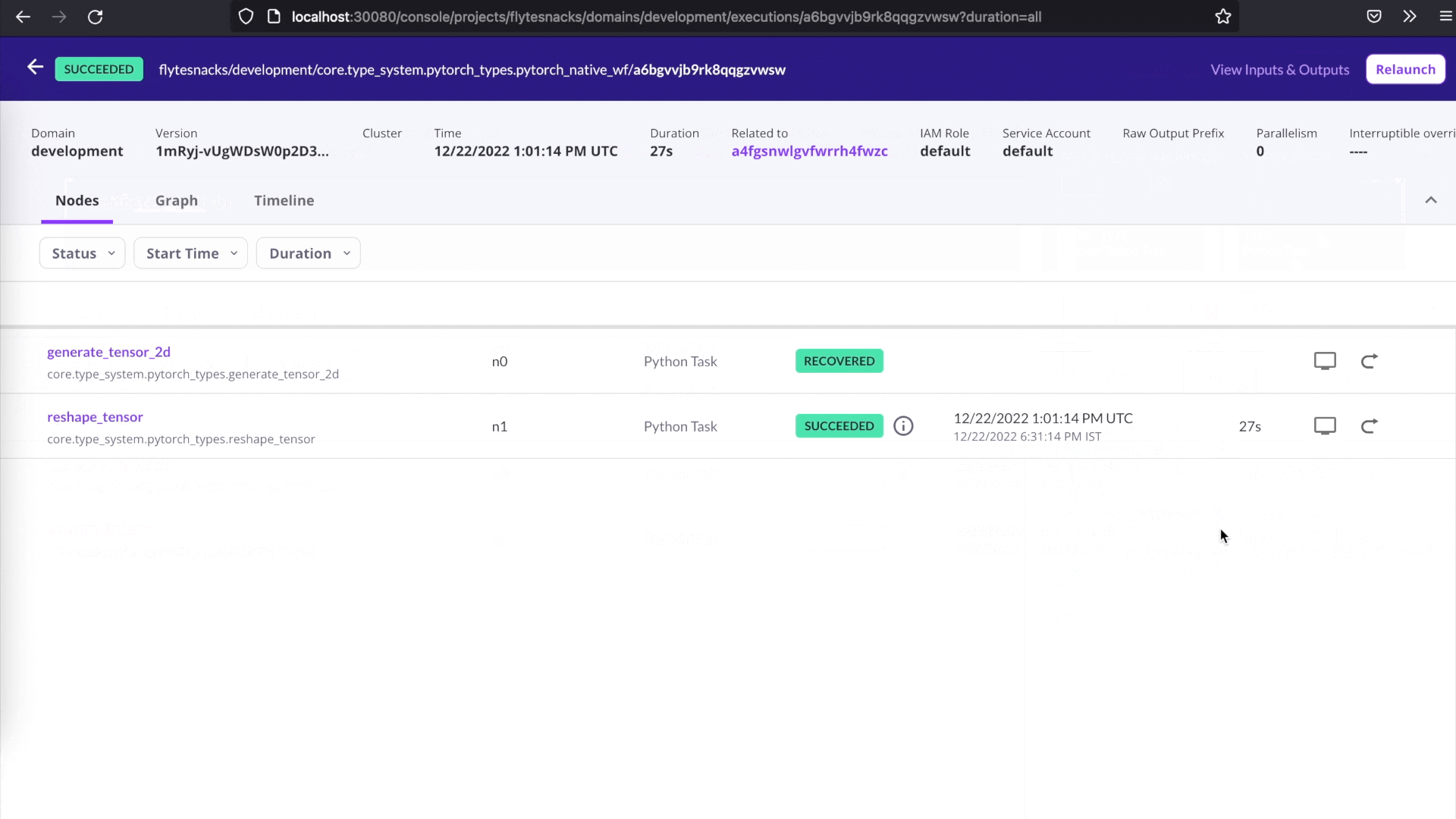
One-click recovery.
Rerun a single task
Debug issues quickly: Rerun workflows at the most granular level without modifying the previous state of a data/ML workflow.
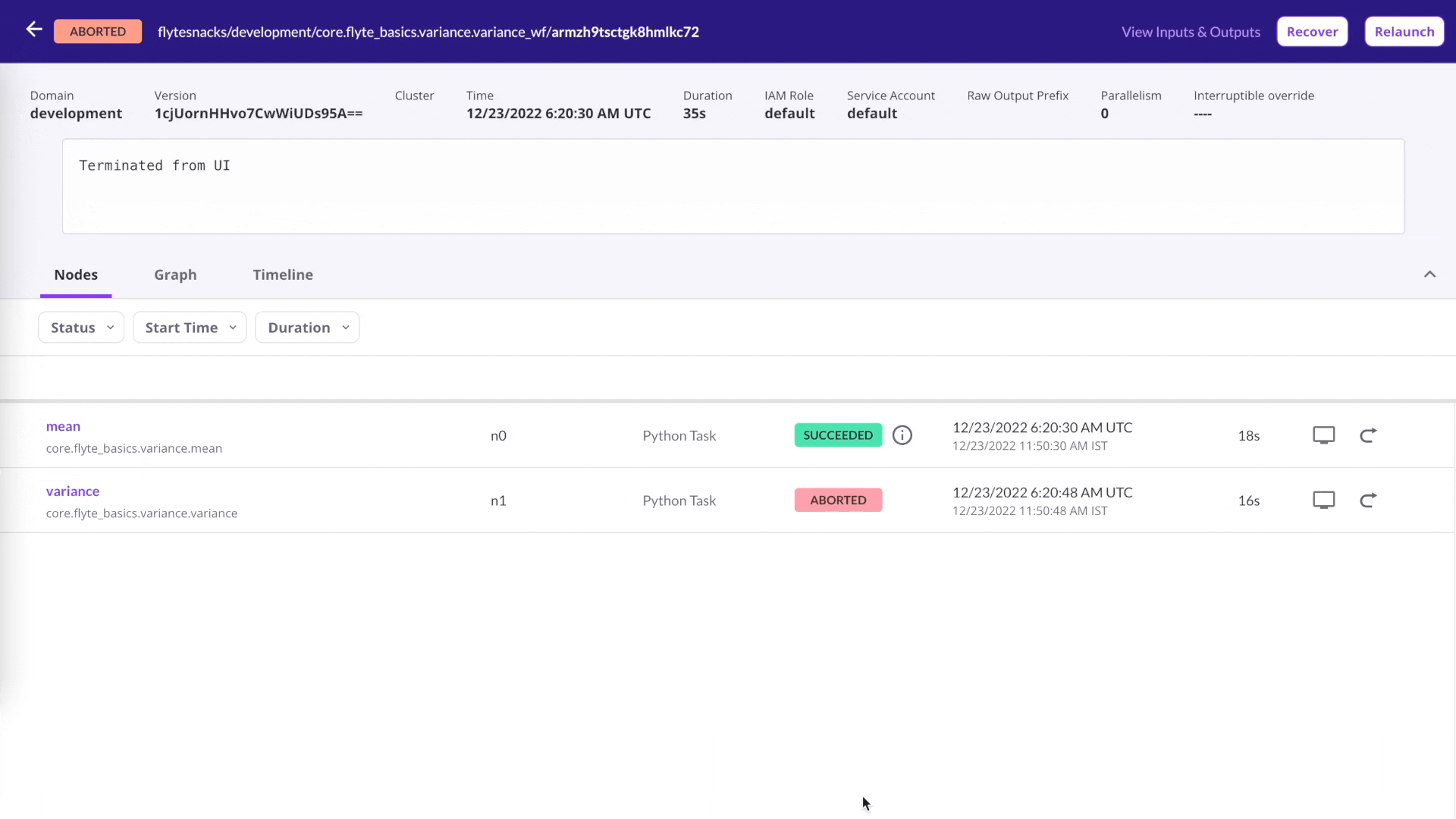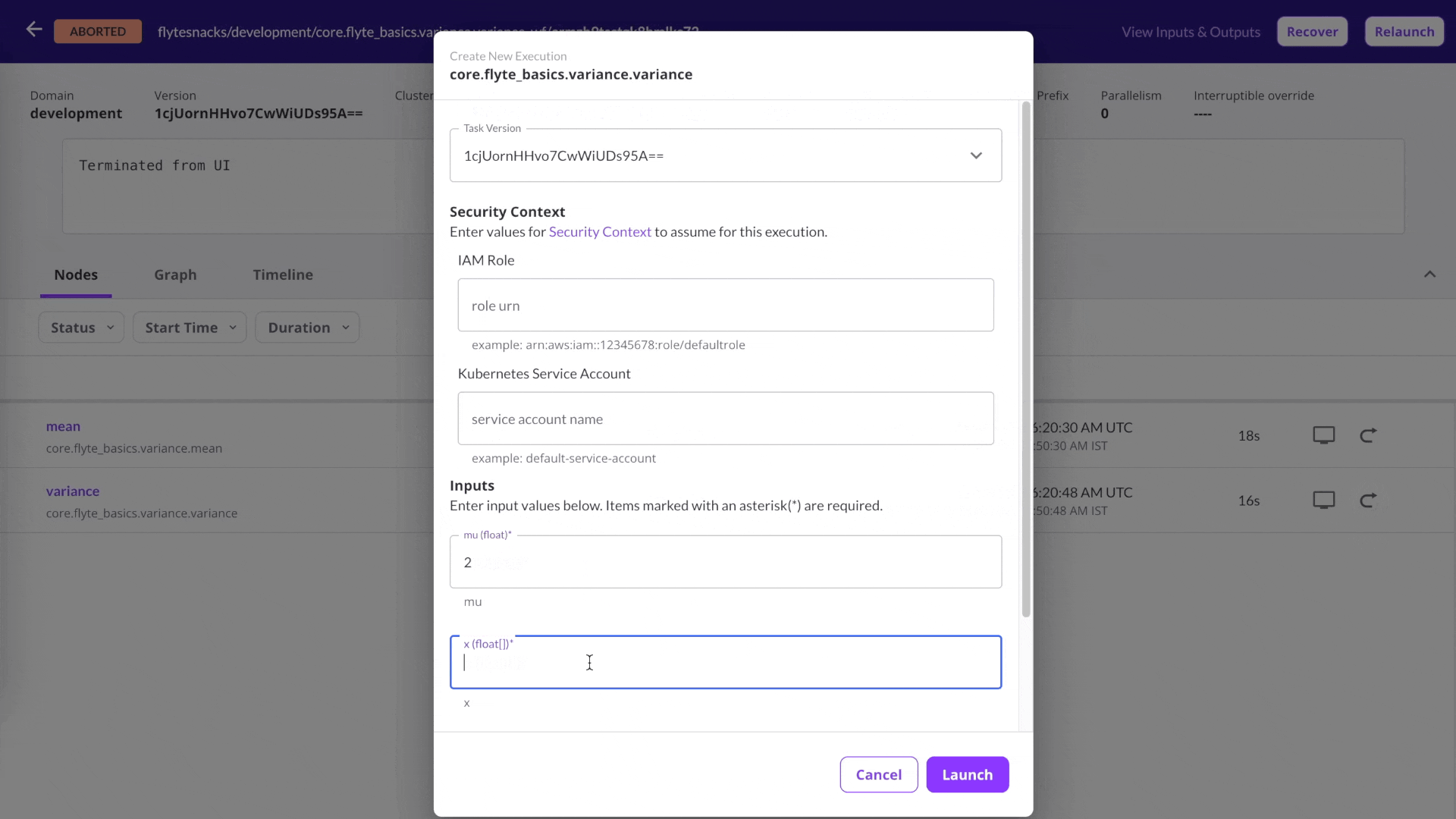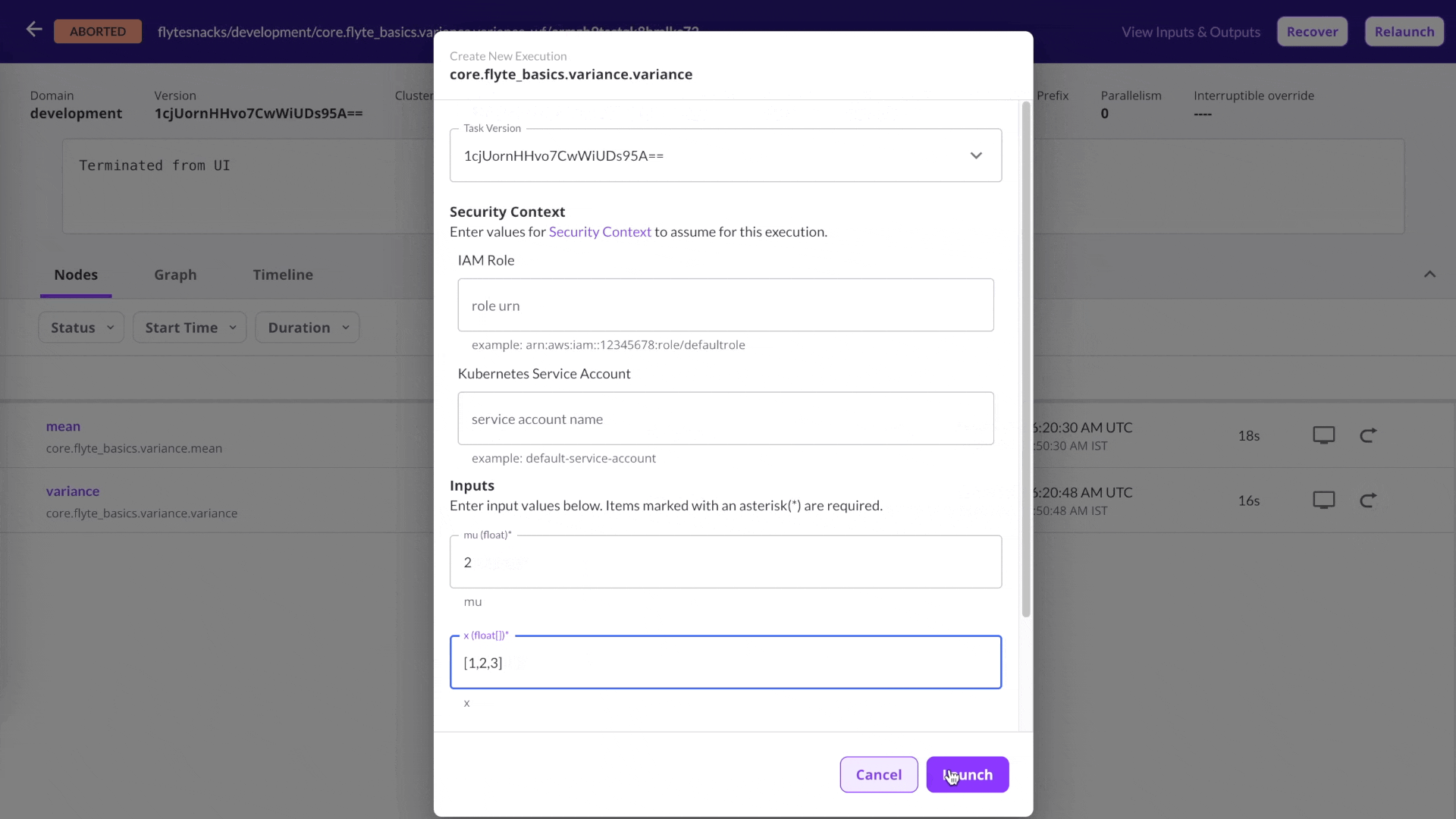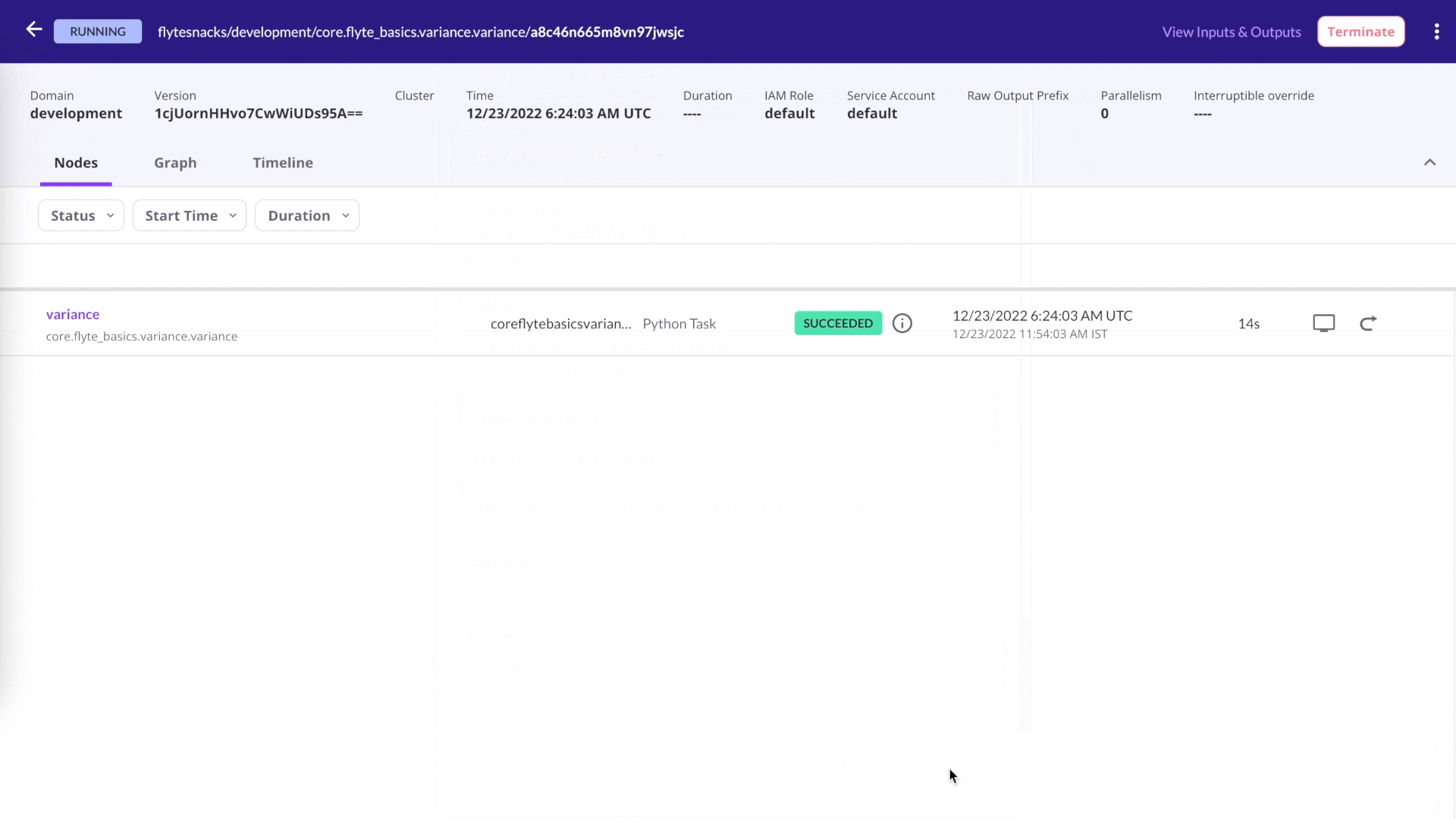
Run Flyte tasks independently any number of times with the click of a button.
Versioned workflows
Data and ML practitioners should be able to experiment in isolation and try multiple iterations. Versioning lets them reproduce results and roll back to a previous workflow version any time. Flyte versions the entire workflow and allows switching versions just like TV channels!
Launching a specific version of the workflow is as simple as selecting the required version.
“Workflow versioning is quite important: When it comes to productionizing a pipeline, there are only a few platforms that provide this kind of versioning. To us, it's critical to be able to roll back to a certain workflow version in case there is a bug introduced into our production pipeline.”
Pradithya Aria Pura, Principal Software Engineer at Gojek
Cache outputs
Don’t waste resources while iterating on data/ML workflows. Cache your task outputs by passing the `cache=True` argument to your `@task` decorator to accelerate your runs.
`cache_version` is helpful to invalidate the previous cache if task functionality changes.
Intra-task checkpointing
Flyte task boundaries are natural checkpoints. They can be expensive, however, in scenarios, such as training a model: Training can be time-consuming and resource-intensive. Intra-task checkpoints in Flyte help checkpoint progress within a task execution.
Checkpointing saves the model state and the number of epochs.
Multi-tenancy
Multi-tenancy supports a centralized infrastructure for your team and organization, so multiple users can share the same platform while maintaining their own distinct data and configurations. Flyte is multi-tenant at its core. That’s important for managing and organizing resources effectively as well as facilitating team collaboration within your organization.
Effortlessly reference a Flyte task (and a workflow) to foster collaboration among teams.

“The multi-tenancy that Flyte provides is obviously important in regulated spaces where you need to separate users and resources and things like amongst each other within the same organization.”
Jake Neyer, Software Engineer at Striveworks

“We get a lot of reusable workflows, and it makes it fairly easy to share complex machine learning and different dependencies between teams without actually having to put all the dependencies into one container.”
Bernhard Stadlbauer, Data Engineer at Pachama
Timeout
To ensure that a system is always making progress, tasks must end reliably. Flyte lets you define a timeout period, after which the task is marked as failure.
Task execution will be terminated if the runtime exceeds 1 hour.

“Because we are a spot-based company, a lot of our workflows run into the majority of issues. Thankfully, with Flyte, we can debug and do quick iterations.”
Varsha Parthasarathy, Senior Software Engineer at Woven Planet
Immutability
Immutable executions help ensure reproducibility by preventing any changes to the state of an execution. This lets you completely restructure a data/ML workflow between versions without worrying about potential deficits in production. Flyte maintains immutability in your workflows.


“Flyte has this concept of immutable transformation — it turns out the executions cannot be deleted, and so having immutable transformation is a really nice abstraction for our data-engineering stack.”
Jeev Balakrishnan, Software Engineer at Freenome
Analyze
Get visibility into your data at every step of your data/ML workflow, across versions. Avoid the uncertainty of the “data blackbox.”
Data lineage
Data lineage can help find the cause of an error. Track the movement and transformation of data throughout the lifecycle of your data and ML workflows with Flyte.
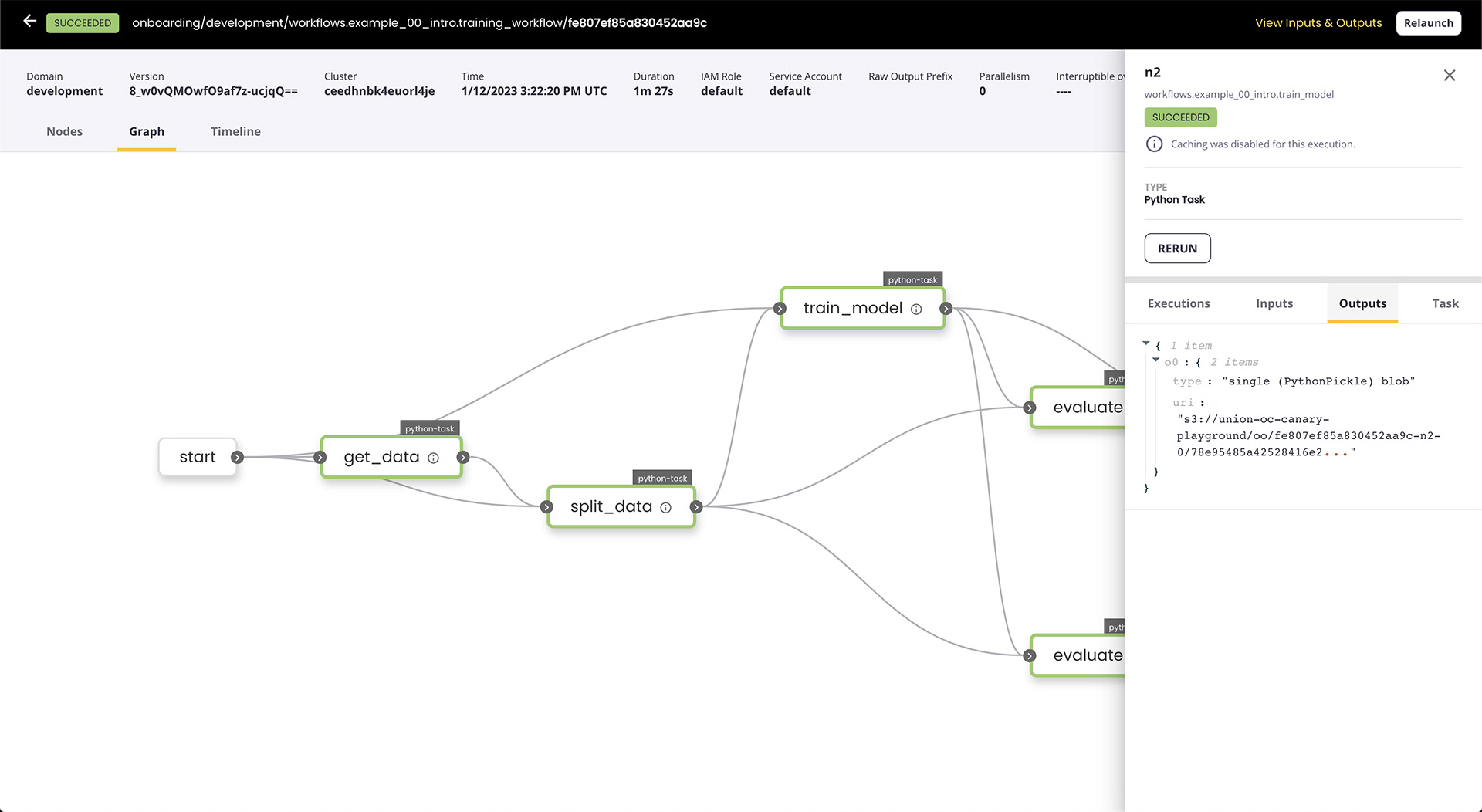
Visualize
Visualization makes data easier to comprehend. Flyte provides first-class support for rendering data plots.
Data visualization
Use FlyteDecks to visualize data, monitor models and view training history through plots.
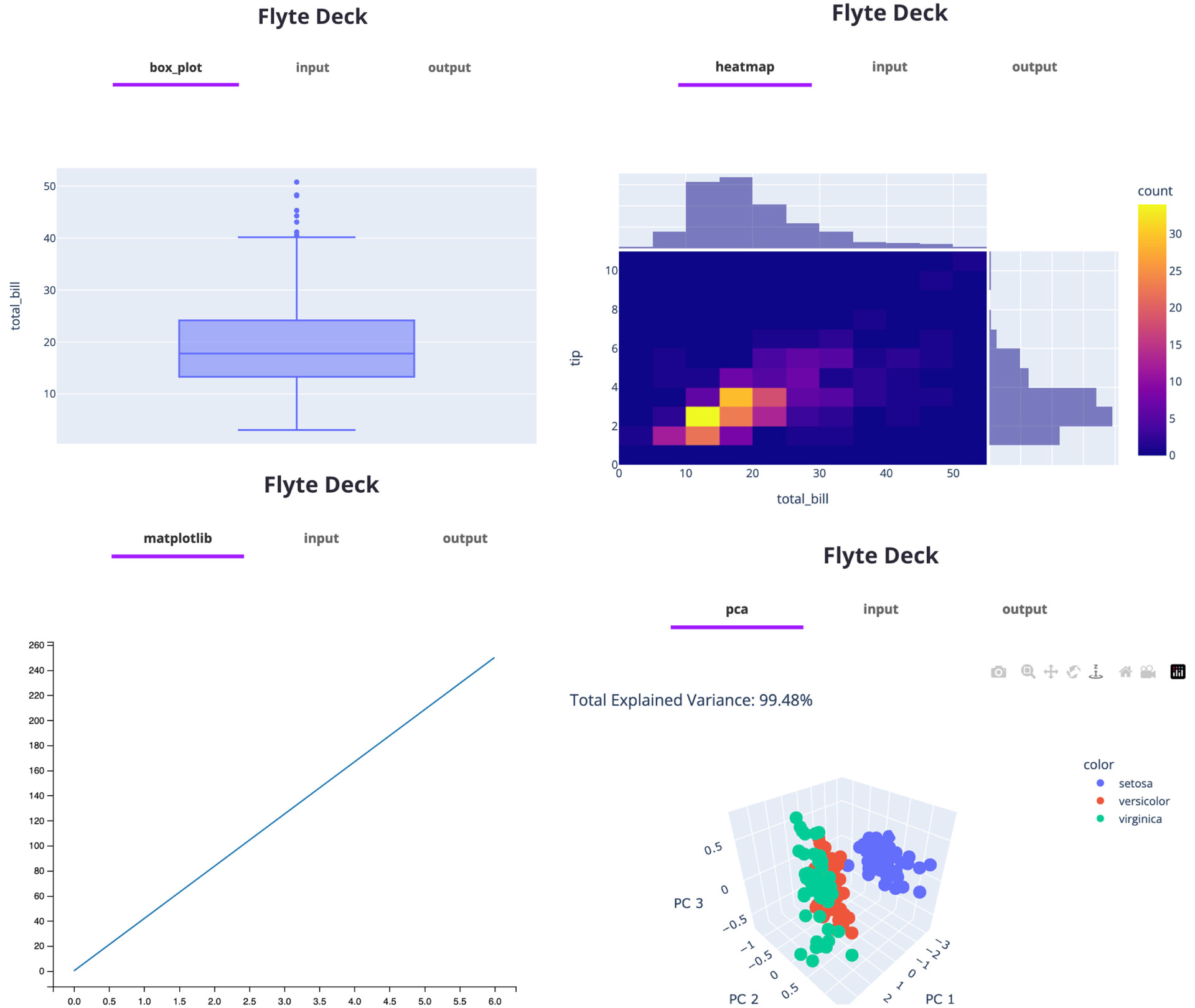
Plots generated with FlyteDecks.
Deploy
Deployment shouldn’t be a tough nut to crack. Flyte’s cost-saving, cloud-native features simplify deployment to the cloud or on-prem.
Dev to prod
Promoting your workflows from development to production is as simple as changing your domain from development or staging to production.

“One thing that I really like compared to my previous experience with some of these tools: the local dev experience with pyflyte and the sandbox are super, super nice to reduce friction between production and dev environment.”
Krishna Yeramsetty, Principal Data Scientist at Infinome
Spot or preemptible instances
Leveraging spot instances doesn’t have to be hard. Schedule your workflows on spot instances by setting `interruptible` to `True` in the `@task` decorator to cut costs.
Scheduling on spot instances is as simple as setting the `interruptible` argument.
“You can say, ‘Give me imputation’ and [Flyte will] launch 40 spot instances that are cheaper than your on-demand instance that you're using for your notebook and return the results back in memory.”
Calvin Leather, Staff Engineer and Tech Lead at Embark Veterinary
“Given the scale at which some of these tasks run, compute can get really expensive. So being able to add an interruptible argument to the task decorator for certain tasks has been really useful to cut costs.”
Jeev Balakrishnan, Software Engineer at Freenome
Cloud-native deployment
Deploy Flyte on AWS, GCP, Azure and other cloud services, and get infinite scalability.

“We're mainly using Flyte because of its cloud native capabilities. We do everything in the cloud, and we also don't want to be limited to a single cloud provider. So having the ability to run everything through Kubernetes is amazing for us.”
Maarten de Jong, Python Developer at Blackshark.ai
Scheduling
Use Flyte to schedule your data and machine learning workflows to run at a specific time.
The workflow is set to run at 1 a.m. every day.
Secrets
Access secrets in your Flyte tasks, whether locally or remotely, by mounting them as files or environment variables.
Monitor
Keep tabs on the status of your data/ML workflows with Flyte. Identify potential bottlenecks to debug issues quickly.
Notifications
Stay informed about changes to your workflow's state by configuring notifications through Slack, PagerDuty or email.

Timeline view
Use the timeline view to evaluate the duration of each of your Flyte tasks and identify potential bottlenecks.
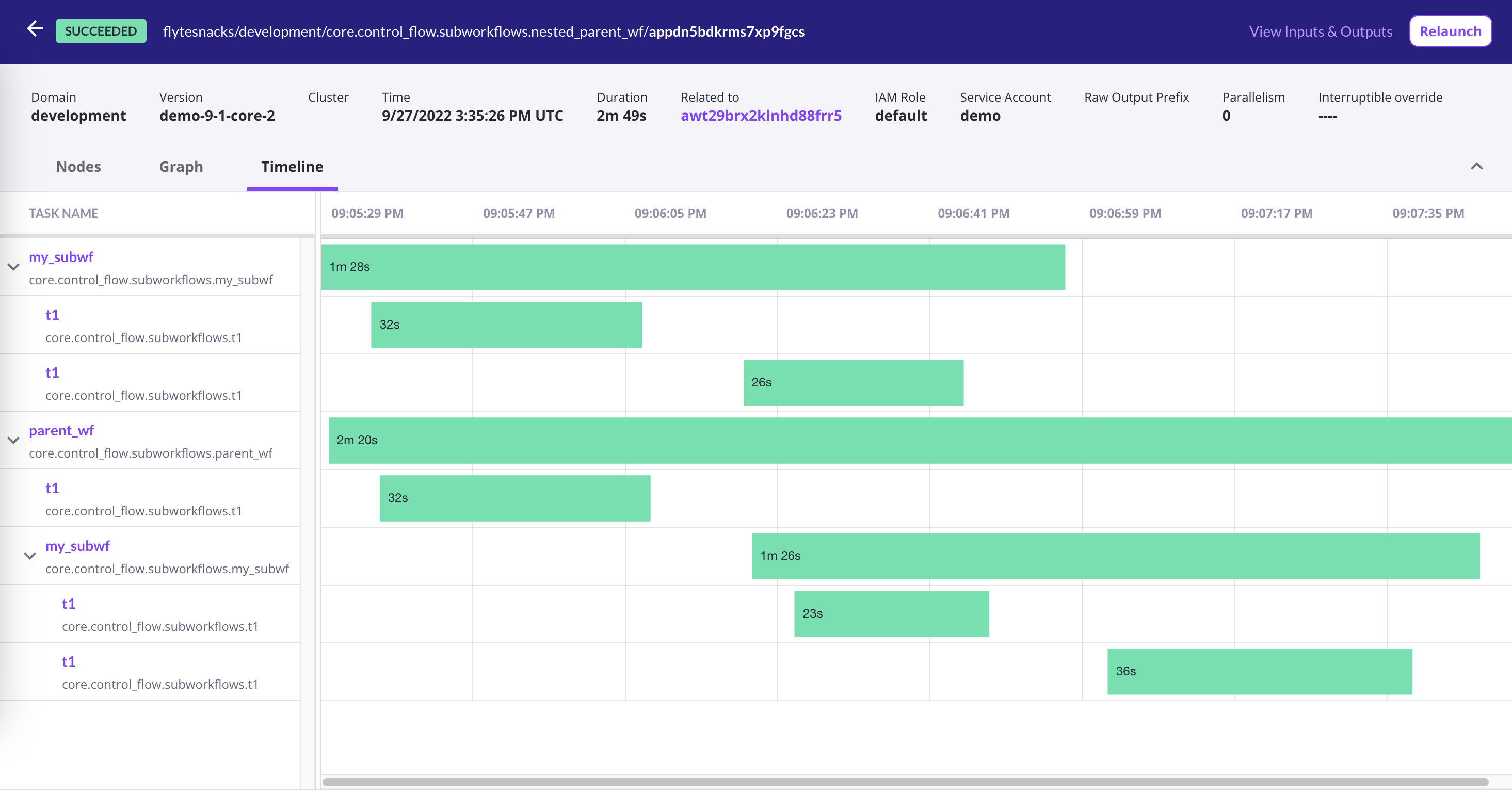
Scale
Flyte is built for high performance. Effortlessly scale your data and ML workflows leveraging the infrastructure-as-code approach.
GPU acceleration
GPUs are becoming essential to run data and ML workflows. Enable and control your tasks’ GPU demands by requesting resources in the `@task` decorator — just like that!
Request GPUs and control the usage by setting limits.
Dependency isolation via containers
Different tasks may have different resource requirements and library dependencies. That can cause conflicts if they aren’t managed carefully. With Flyte, you can maintain separate sets of dependencies for your tasks so no dependency conflicts arise.
No more dependency hell!
Parallelism
Flyte tasks are inherently parallel to optimize resource consumption and improve performance, so you don't have to do anything special to enable parallelism.


“When you write Python scripts, everything runs and takes a certain amount of time, whereas now for free we get parallelism across tasks. Our data scientists think that's really cool.”
Dylan Wilder, Engineering Manager at Spotify
Allocate resources dynamically
Sometimes, the resources needed for a task may depend on user-provided inputs or real-time resource calculations. Flyte makes it easy to allocate resources using the `with_overrides` method and dynamic workflows. This allows you to adjust resources on the fly, ensuring that your tasks have the resources they need to run efficiently.
Override the default resources of a task from within a Flyte workflow in mere seconds.
