Flyte
AI orchestration in pure Python. Open source and trusted by leading AI labs and Fortune 500 companies.
Flyte 2 is available today locally.
For distributed execution, try Flyte 1.
























Introducing Flyte 2
The most intuitive, developer-loved way to orchestrate AI workflows in open source. Now available for local execution.
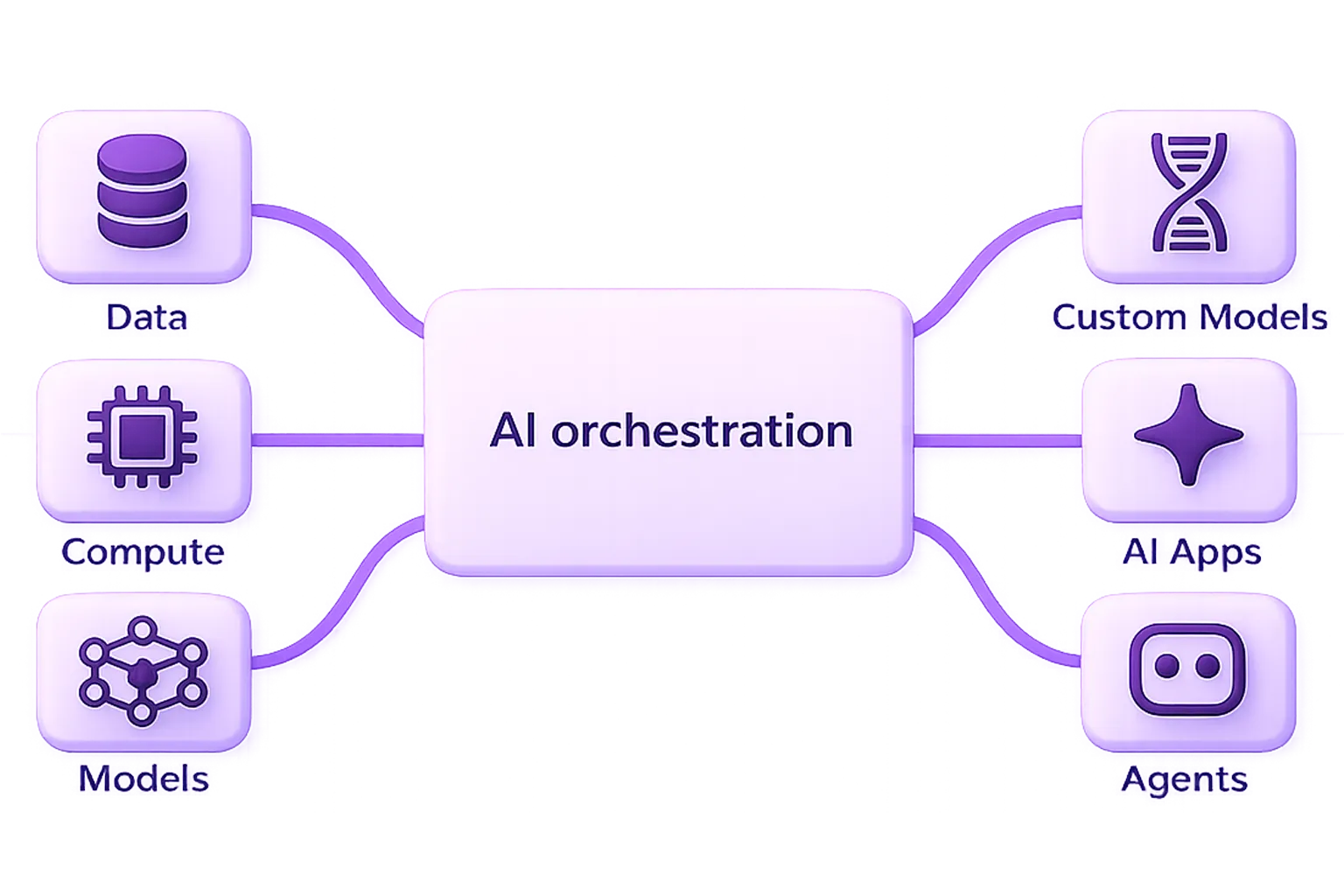
AI orchestration & runtime
Dynamically orchestrate complex, long-running, and agentic workflows with autoscaling and infrastructure awareness.

Author in pure Python
Write workflows in actual Python, no need to learn a DSL. Write, test, and version workflows locally, then run them at scale.
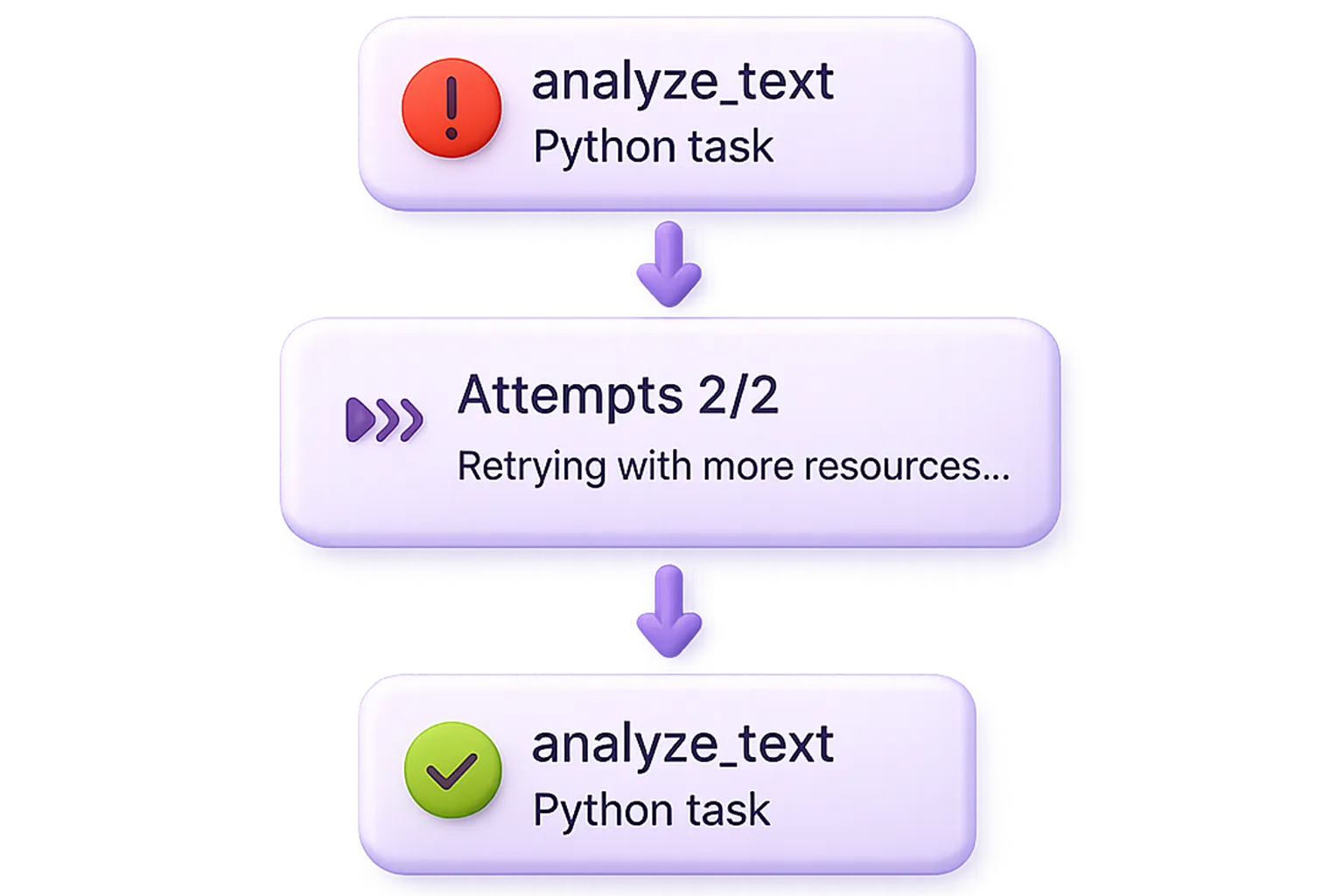
Durable by default
Build fault-tolerant, resilient workflows that retry automatically, pick up where they leave off, and make failures inconsequential.
Choose your engine
Flyte 2 OSS
Build durable AI/ML pipelines and agents with OSS.
Open-source
Build and scale dynamic AI/ML workflows using Flyte’s open-source platform and community.
Infra-aware orchestration
Author in pure Python to provision and scale resources for workflows.
Dynamic workflow execution
Workflows can make on-the-fly decisions at runtime with real-time logic, conditions, and retries.
Self-healing workflows
Workflows can autonomously recover from failures and continue where they left off.
Run locally
Test and debug tasks in your local environment using the same Python SDK that runs in production on Kubernetes.
Union.ai
The enterprise Flyte platform. Build scalable AI and agents in your cloud.
Everything in Flyte 2 OSS, plus:
Massive scale at 50k+ actions/run
Massive scale and ultra-low latency to accelerate AI from experiment to production
Orchestrate, train, and serve
Orchestrate, deploy, and optimize AI/ML systems one unified platform.
Real-time inference
Serve performant agents and models with sub-second latency.
Live remote debugger
Debug remote tasks, line-by-line, on the actual infrastructure where your tasks run.
Reusable, warm-start containers
Achieve task startup time of <100ms by eliminating cold starts.
Observability
Get visibility into resource usage, data lineage, and versioning.
White-glove support
Get dedicated help from a team of expert AI engineers.
Make your AI, ML, and agentic workflows fly.
Build dynamic, self-healing workflows in open source. Our infra-aware platform orchestrates data, models, & compute.







Expand your workflows with powerful integrations.

Apache Spark
Run Spark jobs on ephemeral clusters.
BigQuery
Query a BigQuery table.
PyTorch Elastic v1
Pytorch-native multi-node distributed training.
Ray
Connect to Ray cluster to perform distributed model training and hyperparameter tuning.
Snowflake
Query a Snowflake service.
Weights & Biases v1
Best in class ML/AI experiment- and inference-time tracking.
